- AI
- Application
- Base64Helper
- Browser
- Converter
- Credentials
- Database
- Excel
- File
- Form
- Gherkin
- GoogleDorking
- GoogleDrive
- GoogleSheets
- Grid
- ImageHelper
- Launcher
- Logger
- PuppeteerClient
- RESTClient
- Selector
- Url
Browser
- Navigation
- Tabs and Windows
- Selector Targeting
- Mouse and Keyboard
- Form Data Entry
- File Downloads, Uploads, and Export
- Scrolling, Waiting, and Pagination
- Waiting for Elements, State, and Time (WaitFor)
- Callbacks and Conditional Logic
- Browser Settings and Engine
- Data Retrieval
- Element Attributes
- JavaScript Execution and Storage
- Script Injection
- Stealth and Anti-Detection
Browser
Data Retrieval
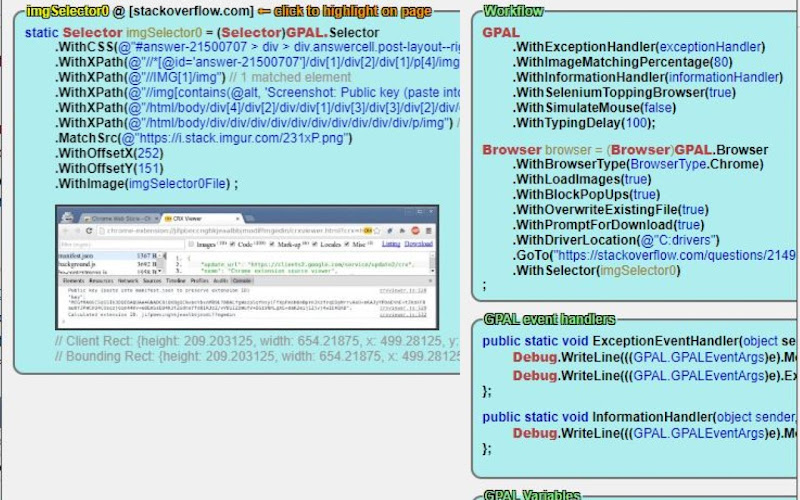
GetGrid retrieves the matched selector data into an IGPALGrid<string> for further processing. GetPageSource extracts the full HTML of the current page. GetSiteMap retrieves the sitemap XML and GetSiteMapUrls returns the individual URLs as a list. GetHydratedData extracts Next.js hydration data embedded in the page. GetLLMDigest produces a cleaned, structured summary of the page content optimized for use as LLM input. The Save variants write these outputs directly to files.
Examples
//GetGrid populates the out parameter with a grid where each row corresponds to one matched element. Columns in the grid correspond to the element attributes GPAL extracts based on the selector configuration.
// Extract a table to a grid
var grid = GPAL
GPAL
// Get page HTML source
string html;
GPAL
// Get all URLs from a sitemap
List<string> urls;
GPAL
Documentation Example
Documentation
Showing off some plain text in these paragraphs eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Category
-
Endpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
Other formats
Here you can find different accents and emphasis sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
This is a link and how it could look like bestlinkinthebeautifulworld. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Here's just some classic bold text adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam notBoldSecondbestlinkinthebeautifulworld illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at adipisicing elit libero vel voluptas? Expedita, adipisicing facere dolores voluptatem ad ab rem assumenda soluta!
Other cuple of colors in case we want to emphasize several ways adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at voluptatem libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Adding Images to the content
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Coding Blocks
Lorem ipsum dolor sit amet consectetur adipisicing elit. Repudiandae quas consequuntur illo numquam assumenda autem exercitationem distinctio perspiciatis in natus. Eius dicta similique ipsam ipsa minima, nemo quae enim tempore.
GPAL
.CallIfNotFound(GenericCallIfNotFound)
.WithPublishToConsole();
//System.Drawing.Rectangle windowSize = new System.Drawing.Rectangle(10, 10, 1500, 1024);
// NOTE: we have to set browser = before we execute any steps
// this is due to the 'GenericCallIfNotFound' which might throw an exception, and BankScraper will not have the browser set when it calls scraper.Close()
// until the complete fluent line gets executed (meaning every step, meaning browser is not set until everything else succeeds)
browser = GPAL.Browser
.WithBrowserType(Enums.BrowserType.Chrome)
.WithProfileDataDirectory(ChromeProfileLocation)
.WithUseAutomationEngine(AutomationEngine.Selenium)
.WithWindowSize(new System.Drawing.Rectangle(0,0,1920,1080))
.ToGPALObject();
Documentation
Showing off some plain text in these paragraphs eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Category
-
Endpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
Other formats
Here you can find different accents and emphasis sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
This is a link and how it could look like bestlinkinthebeautifulworld. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Here's just some classic bold text adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam notBoldSecondbestlinkinthebeautifulworld illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at adipisicing elit libero vel voluptas? Expedita, adipisicing facere dolores voluptatem ad ab rem assumenda soluta!
Other cuple of colors in case we want to emphasize several ways adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at voluptatem libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Adding Images to the content
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta! Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta! Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Coding Blocks
Lorem ipsum dolor sit amet consectetur adipisicing elit. Repudiandae quas consequuntur illo numquam assumenda autem exercitationem distinctio perspiciatis in natus. Eius dicta similique ipsam ipsa minima, nemo quae enim tempore.
GPAL
.CallIfNotFound(GenericCallIfNotFound)
.WithPublishToConsole();
//System.Drawing.Rectangle windowSize = new System.Drawing.Rectangle(10, 10, 1500, 1024);
// NOTE: we have to set browser = before we execute any steps
// this is due to the 'GenericCallIfNotFound' which might throw an exception, and BankScraper will not have the browser set when it calls scraper.Close()
// until the complete fluent line gets executed (meaning every step, meaning browser is not set until everything else succeeds)
browser = GPAL.Browser
.WithBrowserType(Enums.BrowserType.Chrome)
.WithProfileDataDirectory(ChromeProfileLocation)
.WithUseAutomationEngine(AutomationEngine.Selenium)
.WithWindowSize(new System.Drawing.Rectangle(0,0,1920,1080))
.ToGPALObject();