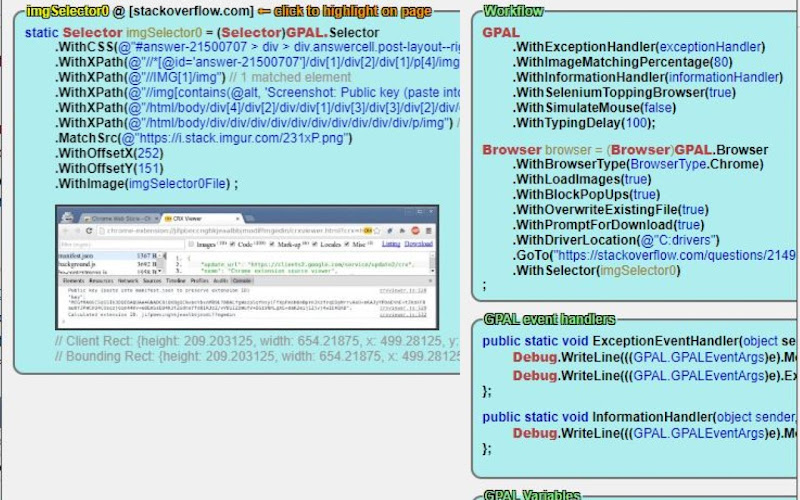
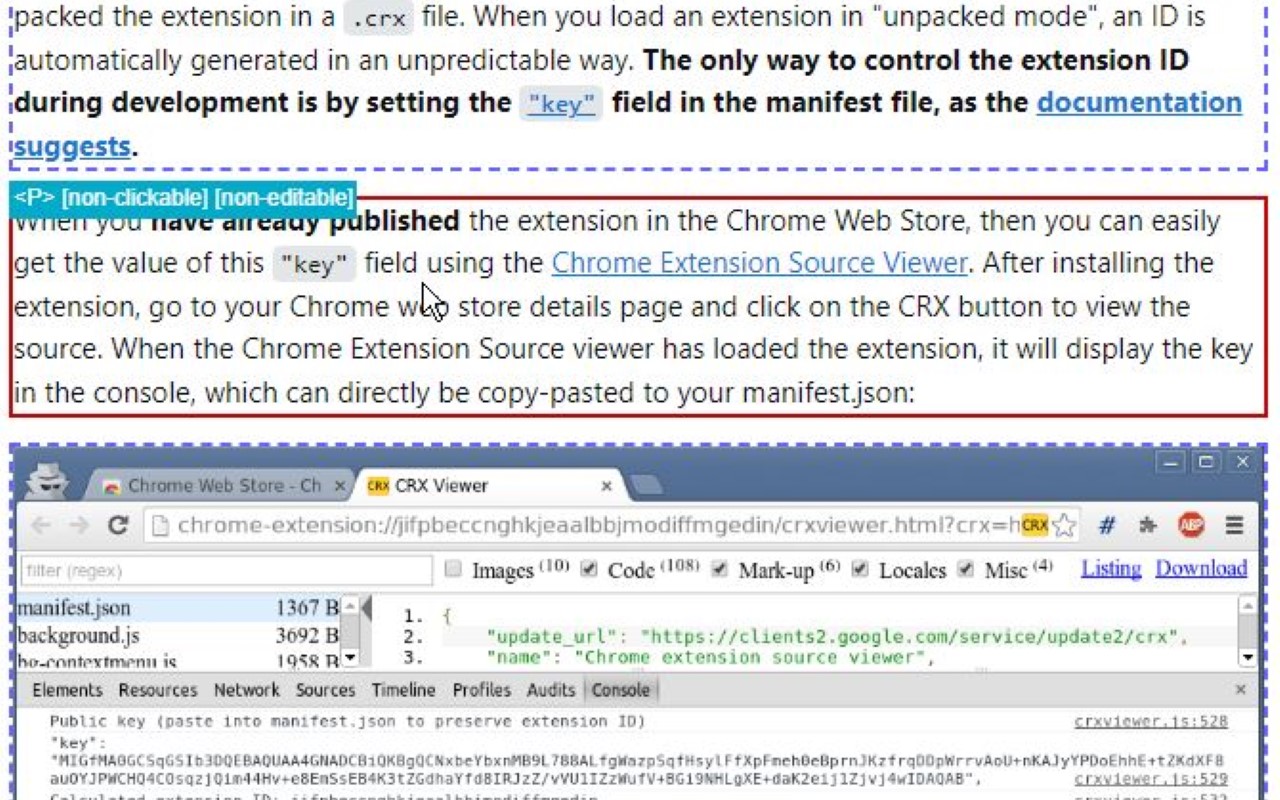
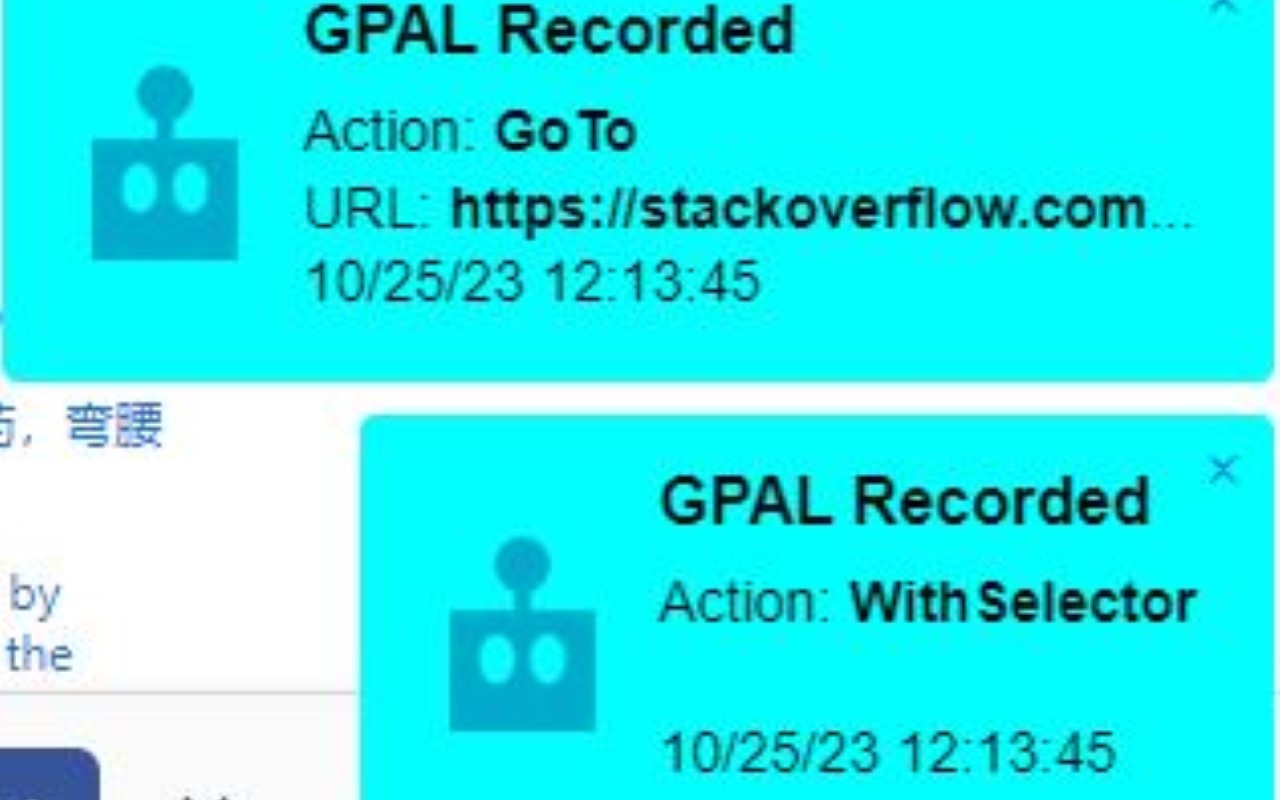
- A Minimal OttoMagic Smoke Test
- Automating a Desktop App: Notepad++
- Automating a Login Flow with a Native Menu Selection
- Automating Microsoft Teams with Desktop Application Selectors
- Automating YouTube Studio: Navigating a Multi-Step Upload Dialog
- Behavior-Style Workflows with GPAL.Gherkin
- Building a Form: Controls, FillInFrom, and CallAfterFillIn
- Building a Live AI Summarizer Form
- Calling REST Endpoints with GPAL.RESTClient
- Casting a Tab or Desktop to a Network Device
- Chaining Browser Actions Through GPAL.RESTClient with AndThen
- Chaining Workflows: CallAfterFillIn and CallIfFound Together
- Clicking a Captcha with a GPALForm and Hardware Input
- Cross-Site Workflow: Find a Book, Then Search for It Elsewhere
- Downloading and Patching a Browser Driver Automatically
- Downloading Files with a Right-Click
- Drag and Drop with Image-Based Selectors
- Driving a Browser Directly with PuppeteerClient
- Driving a Live Browser Through GPAL.OttoMagicClient
- Driving a Search Box from a GPALFile of Search Terms
- Driving a Search Form from a Database Table
- Driving Native Dropdown Menus with SelectClick
- Driving Native Dropdowns with SelectClick
- Driving the Browser Through the REST Client
- Dropping Down to PuppeteerCommunicator: Raw Chrome DevTools Commands
- Encryption, Hashing, and Signing with GPAL Cryptography
- Filling In Special-Format Inputs: Color, Date, Time, and More
- GPALConverter: Moving Data Between CSV, JSON, XML, YAML, and Classes
- Handling Cookie Banners and Popups with Persistent Selectors
- Image Matching and Selectors Inside Iframes
- Inside the GPAL REST API Server (OttoMagic's Backend)
- Launching Chrome with a Real Browser Profile
- Layer-by-Layer: Click, Fill In, and Read
- Left Click and Upload: Driving a File Picker
- Left-Click and Download a File
- Logging to a Database and Sending Email with GPAL
- Pacing a Workflow with WaitFor
- Paging with Workflows: While and Until
- Reading, Writing, and Clearing Browser Storage
- Reading, Writing, and Formatting Google Sheets
- Recording and Replaying a Selector Sequence
- Searching the Web with GPAL.GoogleDorking
- Talking to an OpenAPI-Described Service
- Testing Stealth Against Anti-Bot Detection Sites
- Walking Sitemaps and Capturing Page Digests
- Working with Spreadsheets: GPAL.Excel End to End
Tutorials
Walking Sitemaps and Capturing Page Digests
GetSiteMapUrls walks a site's sitemap.xml so you can discover pages without hand-coding URLs, and GetHydratedData / GetLLMDigest pull structured and LLM-friendly summaries out of each page you visit. This tutorial crawls a sitemap, captures a modern framework's hydration data, and saves an LLM digest for every page using GPALFile.Next.
Complete Program
Here's the whole workflow, start to finish. Each piece is broken down and explained below.
using System.Collections.Generic;
using GenerallyPositive;
using GenerallyPositive.Browser;
using static GenerallyPositive.Enums;
GPAL
.WithPublishToConsole()
.WithDriverLocation(@"C:drivers")
.WithUseOttoMagic(@"C:OttoMagic");
IBrowser browser = GPAL.Browser
.WithBrowserType(BrowserType.Chrome)
.WithUseStealth(StealthType.GoogleReferrer | StealthType.PatchChromeDriver | StealthType.DarkMode)
.WithUseAutomationEngine(AutomationEngine.OttoMagic)
.WithRespectRobotMetaTags(true)
.WithObeyRobotsTxt(true)
.ToGPALObject();
string siteUrl = "Nike.com";
List<string> sitemapUrls;
browser.GoTo(siteUrl).WaitFor(2_000)
.GetSiteMapUrls(out sitemapUrls);
foreach (string url in sitemapUrls)
{
List<string> nestedUrls;
browser.GoTo(url).WaitFor(2_000)
.GetSiteMapUrls(out nestedUrls);
foreach (string nestedUrl in nestedUrls)
{
browser.GoTo(nestedUrl).WaitFor(5_000);
GPAL.PublishSimpleEvent(GPALEventType.INFO, $"Visited [{nestedUrl}]");
}
}
NextJsHydrationResult nextJsHydrationResult;
LLMDigestResult digestResult;
GPALFile hydratedDataFile = @"c:sdihydratedData.txt";
GPALFile llmDigestFile = @"c:sdillmDigest.txt";
browser.GoTo(siteUrl).WaitFor(5_000)
.GetHydratedData(out nextJsHydrationResult);
browser.SaveHydratedData(hydratedDataFile);
browser
.GetLLMDigest(out digestResult)
.SaveLLMDigest(llmDigestFile.Next);
browser.Close(true);
Walking a Sitemap with GetSiteMapUrls
GetSiteMapUrls reads the current page's sitemap (sitemap.xml or whatever robots.txt points to) and returns the URLs it lists. Top-level sitemaps often list other sitemaps - category or product feeds - rather than pages directly, so calling GetSiteMapUrls again on each result walks down a level. This nested loop visits every URL two levels deep.
List<string> sitemapUrls;
browser.GoTo(siteUrl).WaitFor(2_000)
.GetSiteMapUrls(out sitemapUrls);
foreach (string url in sitemapUrls)
{
List<string> nestedUrls;
browser.GoTo(url).WaitFor(2_000)
.GetSiteMapUrls(out nestedUrls);
foreach (string nestedUrl in nestedUrls)
{
browser.GoTo(nestedUrl).WaitFor(5_000);
GPAL.PublishSimpleEvent(GPALEventType.INFO, $"Visited [{nestedUrl}]");
}
}
A site's top-level sitemap.xml frequently lists other sitemaps (products.xml, categories.xml, and so on) instead of pages. Call GetSiteMapUrls again on each entry to walk down to the actual page URLs.
Browsing Politely: Stealth and robots.txt
WithRespectRobotMetaTags and WithObeyRobotsTxt tell GPAL to honor a site's crawling rules - robots meta tags on individual pages and the site-wide robots.txt - the same way a well-behaved crawler would. WithUseStealth applies a combination of techniques so the automated browser looks more like a normal visit; StealthType is a flags enum, so OR several together with |.
IBrowser browser = GPAL.Browser
.WithBrowserType(BrowserType.Chrome)
.WithUseStealth(StealthType.GoogleReferrer | StealthType.PatchChromeDriver | StealthType.DarkMode)
.WithUseAutomationEngine(AutomationEngine.OttoMagic)
.WithRespectRobotMetaTags(true)
.WithObeyRobotsTxt(true)
.ToGPALObject();
Capturing Hydrated Data from Modern Frameworks
Many sites built with frameworks like Next.js fetch data on the server and embed it as JSON for the page to "hydrate" into on load. GetHydratedData reads that embedded JSON into a NextJsHydrationResult, and SaveHydratedData writes it to a GPALFile. Hydration happens after the document is otherwise ready, so this step uses a longer WaitFor than a typical navigation.
NextJsHydrationResult nextJsHydrationResult;
GPALFile hydratedDataFile = @"c:sdihydratedData.txt";
browser.GoTo(siteUrl).WaitFor(5_000)
.GetHydratedData(out nextJsHydrationResult);
browser.SaveHydratedData(hydratedDataFile);
Saving Per-Page Digests with GPALFile.Next
GetLLMDigest produces a condensed, LLM-friendly summary of the current page as an LLMDigestResult, and SaveLLMDigest writes it out. llmDigestFile.Next returns a new GPALFile pointing at the next available filename in sequence (llmDigest1.txt, llmDigest2.txt, ...) without changing llmDigestFile itself - call it fresh inside a loop to give every page its own digest file.
LLMDigestResult digestResult;
GPALFile llmDigestFile = @"c:sdillmDigest.txt";
browser
.GetLLMDigest(out digestResult)
.SaveLLMDigest(llmDigestFile.Next);
llmDigestFile.Next is a fresh GPALFile each time you read it - llmDigestFile itself still points at llmDigest.txt. Reading .Next inside a loop gives you llmDigest1.txt, llmDigest2.txt, and so on, so earlier digests aren't overwritten.
Documentation Example
Documentation
Showing off some plain text in these paragraphs eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Category
-
Endpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
Other formats
Here you can find different accents and emphasis sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
This is a link and how it could look like bestlinkinthebeautifulworld. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Here's just some classic bold text adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam notBoldSecondbestlinkinthebeautifulworld illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at adipisicing elit libero vel voluptas? Expedita, adipisicing facere dolores voluptatem ad ab rem assumenda soluta!
Other cuple of colors in case we want to emphasize several ways adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at voluptatem libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Adding Images to the content
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Coding Blocks
Lorem ipsum dolor sit amet consectetur adipisicing elit. Repudiandae quas consequuntur illo numquam assumenda autem exercitationem distinctio perspiciatis in natus. Eius dicta similique ipsam ipsa minima, nemo quae enim tempore.
GPAL
.CallIfNotFound(GenericCallIfNotFound)
.WithPublishToConsole();
//System.Drawing.Rectangle windowSize = new System.Drawing.Rectangle(10, 10, 1500, 1024);
// NOTE: we have to set browser = before we execute any steps
// this is due to the 'GenericCallIfNotFound' which might throw an exception, and BankScraper will not have the browser set when it calls scraper.Close()
// until the complete fluent line gets executed (meaning every step, meaning browser is not set until everything else succeeds)
browser = GPAL.Browser
.WithBrowserType(Enums.BrowserType.Chrome)
.WithProfileDataDirectory(ChromeProfileLocation)
.WithUseAutomationEngine(AutomationEngine.Selenium)
.WithWindowSize(new System.Drawing.Rectangle(0,0,1920,1080))
.ToGPALObject();
Documentation
Showing off some plain text in these paragraphs eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Category
-
Endpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
-
Enpoint
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quo veniam mollitia excepturi animi eum illum non libero sapiente provident assumenda, delectus voluptatum nobis sed dolorem adipisci laudantium incidunt. Error, ratione?
Other formats
Here you can find different accents and emphasis sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
This is a link and how it could look like bestlinkinthebeautifulworld. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Here's just some classic bold text adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam notBoldSecondbestlinkinthebeautifulworld illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at adipisicing elit libero vel voluptas? Expedita, adipisicing facere dolores voluptatem ad ab rem assumenda soluta!
Other cuple of colors in case we want to emphasize several ways adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam adipisicing elit illo nostrum corporis at voluptatem libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Adding Images to the content
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta! Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta! Lorem ipsum dolor, sit amet consectetur adipisicing elit. Quod veniam, quam ad expedita laborum sed at voluptates culpa ipsam ut vel. Ullam temporibus a mollitia quod aliquam ratione exercitationem nesciunt.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Obcaecati, iste distinctio veritatis eligendi laboriosam illo nostrum corporis at libero vel voluptas? Expedita, facere dolores voluptatem ad ab rem assumenda soluta!
Coding Blocks
Lorem ipsum dolor sit amet consectetur adipisicing elit. Repudiandae quas consequuntur illo numquam assumenda autem exercitationem distinctio perspiciatis in natus. Eius dicta similique ipsam ipsa minima, nemo quae enim tempore.
GPAL
.CallIfNotFound(GenericCallIfNotFound)
.WithPublishToConsole();
//System.Drawing.Rectangle windowSize = new System.Drawing.Rectangle(10, 10, 1500, 1024);
// NOTE: we have to set browser = before we execute any steps
// this is due to the 'GenericCallIfNotFound' which might throw an exception, and BankScraper will not have the browser set when it calls scraper.Close()
// until the complete fluent line gets executed (meaning every step, meaning browser is not set until everything else succeeds)
browser = GPAL.Browser
.WithBrowserType(Enums.BrowserType.Chrome)
.WithProfileDataDirectory(ChromeProfileLocation)
.WithUseAutomationEngine(AutomationEngine.Selenium)
.WithWindowSize(new System.Drawing.Rectangle(0,0,1920,1080))
.ToGPALObject();